架构评估与治理
一. 背景
架构的混乱程度就是不断熵增的结果
阿里作为大规模的电商公司,随着这么多年的业务发展和技术迭代,可想而知其业务的复杂性和技术的多样性,业务爆发式增长必定带来一个问题:资源分配不合理。也就是说所有的人力倾斜向业务支持,导致了:
- 业务架构越发复杂,多种业务架构并存且相互叠加
- 技术债务越发严重,前面的债务还没解决,新的高优先级的业务需求就来了
- 各种「临时方案」结果成了「永久方案」
- 随着员工的流动,知识库已经结了蜘蛛网,缺失了大量的技术手册和用户手册
不仅如此,由于阿里采用「前台+中台+后台」的组织架构,前台业务和中台业务更关心业务迭代完整度,一切以“业务需求是否能完成”为目标,不关心使用了哪些中间件,这些中间件的版本是新还是旧,也不关系机器资源使用率,甚至一个小的工具都会新开一套集群来进行部署发布。
表面上来看,业务确实得到了很好的支持,也满足了业务方的迭代速度,但是随着上述的问题越积越深,慢慢的债务问题开始暴露出来了:
- 业务方的需求已经无法快速满足了,因为技术债务问题或者架构问题导致了 惊群效应,引一发而动全身
- 机器和中间件使用成本已经达到一个恐怖的数量级,出现了严重浪费
- 相同能力的服务能找到N多个版本,甚至有些版本的内部逻辑是一模一样的
- 大量的僵尸应用和僵尸服务,不知道上游是谁,也不知道下游还存不存活
- ……
治理时机的选择:当出现以下信号时必须启动:
- 新业务接入成本 > 该业务首年预期收益的30%
- 核心系统变更影响分析超过3层调用栈
平均下来,每5-7年需完成一次架构范式升级
二. 架构评估
1. 质量属性
1.1 性能:
根据处理事务时间定量
- QPS:每秒处理请求数
- TPS:每秒处理事务数
- 并发数:同一时刻处理请求数/事务数
- 响应时间:系统对请求做出响应的时间
- 并发数 = QPS x RT
1.2 可靠性:
通常用平均失效等待时间(MTTF)和平均失效间隔时间(MTBF)来衡量
- 容错:发生异常情况下保证的统正确的行为,可进行内部修复
- 健壮性:保护系统不受错误使用和错误输入的影响
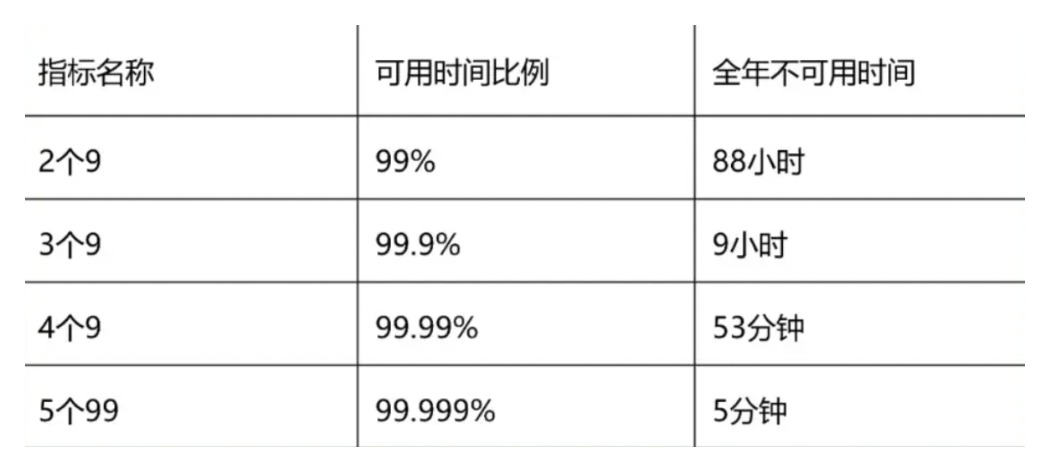
1.3 可用性:
通常用两次故障之间的时间或者故障恢复时间来定量
1.4 安全性:
机密性、完整性、不可否认性、可控性
1.5 可修改性:
- 可维护性:错误发生后,进行局部修复并减少全局影响
- 可扩展性:高内聚低耦合的构建方式
- 可移植性:平台无关性、无状态、减少深度依赖
1.6 功能性:
业务功能的完整性
2. 评估过程:
2.1 敏感点
敏感点是指对架构质量属性有重大影响的决策点,即 某个架构决策的微小变化可能会显著影响系统的性能、可扩展性、可维护性等。
示例:在系统安全中,选择不一样的安全算法可能影响系统的安全级别
2.2 权衡点
权衡点是指架构设计中需要在多个相互冲突的质量属性之间做出权衡的决策点,即 一个架构决策可能会提升某个属性,但会牺牲另一个属性。
示例:在系统安全中,多层叠加后的安全算法可能提高安全等级,但是会影响系统能行
2.3 风险点
风险点是指 在架构设计和实现过程中,可能导致系统失败或不满足需求的潜在问题。风险点通常与 技术选型、架构决策、外部依赖、团队能力等因素相关。
示例:技术不成熟:如果选择一个新的数据库(如 TiDB),但团队缺乏经验,可能会导致项目失败
小结: 敏感点决定了关键的架构影响因素,权衡点要求架构师在多个方案之间做出合理选择,风险点则是架构决策可能导致的潜在问题。
3. 评估方法
评估方法:ATAM(Architecture Tradeoff Analysis Method)由卡梅隆大学软件工程协会提出,是一种基于场景的架构评估方法,核心是结合质量属性效用树对系统进行评价,确定风险点、敏感点、权衡点,并对系统架构做出决策和折中。
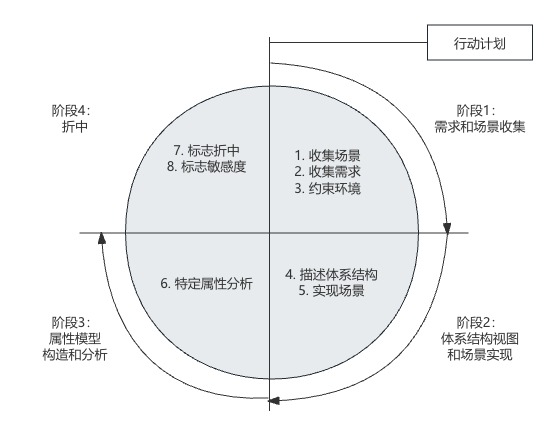
3.1 各个业务方列出核心需求
- 系统在100毫秒内响应用户请求
- 当主数据库发生故障后,10秒内自动切换至从数据库
- 当主机房发生故障后,5分钟内请求重定向至灾备机房
- 新增业务功能,开发工作在5人日内完成
- 使用包含SSL数字证书的HTTPS访问协议
- 界面要求简单易用
- ……
3.2 生成质量属性效用树
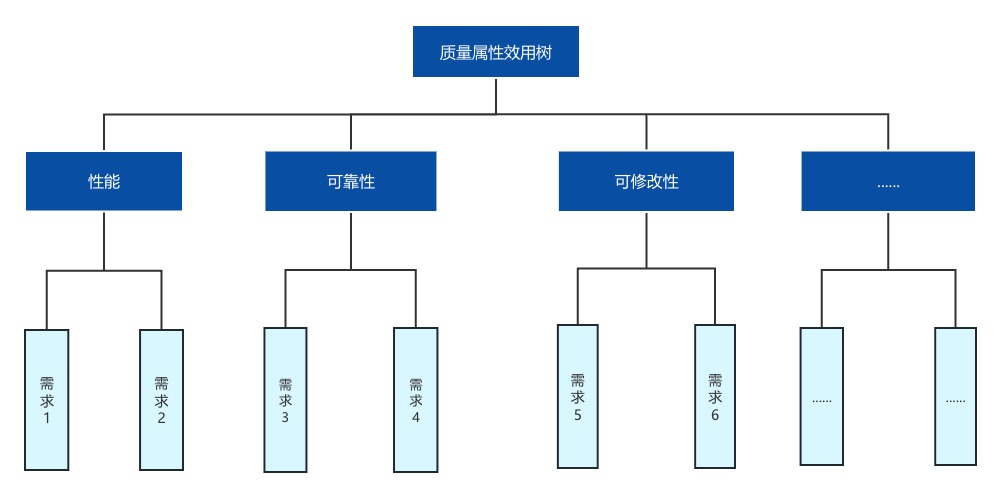
3.3 分析
根据这些场景分析系统的风险点、敏感点、权衡点
3.4 测试
测试阶段,根据系统特性,首先确定场景优先级,由高到低分别是:性能、可靠性、可用性、可修改性、安全性、易用性
3.5 汇总
汇总阶段,将评估过程和结果都汇总整理成文档,其中包括质量属性效用树、风险点、敏感点、权衡点、每次评估会议纪要以及最终架构决策
三. 架构治理过程
从架构师视角出发,面对研发效率低下和技术债务堆积的问题,可以通过以下系统化的方式诊断和优化,确保解决方案兼顾短期见效和长期可持续性:
1. 深度诊断
1.1 效率瓶颈量化
- 交付流程度量:
- 统计关键指标:需求交付周期(从需求提出到上线)、部署频率(每周/月部署次数)、变更失败率(回滚/故障率)
- 使用价值流分析(Value Stream Mapping) 绘制需求从提出到上线的全流程,识别阻塞点(如需求评审卡顿、测试环境等待)
- 团队协作诊断:
- 例:每日会议是否超过2小时?、联调等待时间是否超过1天?
- 分析代码库日志,识别高频修改的耦合模块(如订单中心被5个团队频繁修改)
1.2 技术债务
- 架构健康度评估:
- 业务功能的完整度、服务性能、包冗余等等。
- 识别高风险债务:如无降级的单点服务、过时组件等
- 债务成本量化:
- 计算债务维护成本(例:每月30%开发时间用于修复旧Bug)
- 评估业务影响:如因库存服务响应慢导致大促超卖损失
3. 根因汇总
- 流程类:需求频繁变更(月均变更率40%)、手工部署(每次部署需2小时)
- 技术类:订单服务与物流服务强耦合(修改需同步发布)、无自动化测试(测试覆盖<30%)
- 组织类:能否划分到具体责责人
2. 优化方案
2.1:止血与快速提效
- 流程优化
- 债务紧急处理
- 环境治理
2.2 体系化能力建设
- 架构解耦
- 质量内建
- 知识沉淀
3. 长效预防机制(持续运行)
3.1 债务防控体系
- 技术债务看板:标记债务卡片,每迭代预留15%容量处理
- 合并门禁:PR需通过质量扫描(覆盖率>60%+无严重Bug)
3.2 效能度量闭环
- 仪表盘展示:部署频率、平均修复时间(MTTR)、需求吞吐量
- 效能复盘:根据数据调整流程(如发现代码评审是瓶颈,则优化评审机制)
3.3 组织保障
- 设立架构治理小组:评审重大变更,否决高风险方案
- 将债务清理纳入工程师工作量指标
四. 阿里国际架构中心落地
集合上述背景和方法论,阿里国际决定开始展开架构治理工作,成立了架构委员会,专项治理架构债务和用户痛点, 从成本、效率、风险等方面进行考察和提升,联合阿里云、研发效能平台、中间件等团队,打造架构中心可视化大盘,对现存的应用、镜像、模块进行全方位扫描,梳理出:
- 流量调用链路 以及 调用频率等
- 中间件使用情况,用了哪些中间件,以及中间件的调用频率
- 机器资源使用情况,包括 CPU使用率、内存使用率等
- 包依赖tree,版本tree
- 服务的发布效率、发布频率
- 需求的影响速度,服务的迭代速度
- 服务的维护成本,包括机器成本、开发成本和维护成本
- 客户答疑采纳率等
- ……
分析点:
- 服务的上下游依赖是否清晰,消除冗余,保留核心
- 应用和服务是否已经很长时间没有流量了,是否长久占用机器资源或者链接资源
- 应用之间的相互依赖是否存在版本不一致的问题,以及二方包版本混乱的问题
- 应用过于臃肿,发布效率低下
- 机器资源利用率合不合理
- 链路是否合理,即是否可以移除不需要的流程节点
- ……
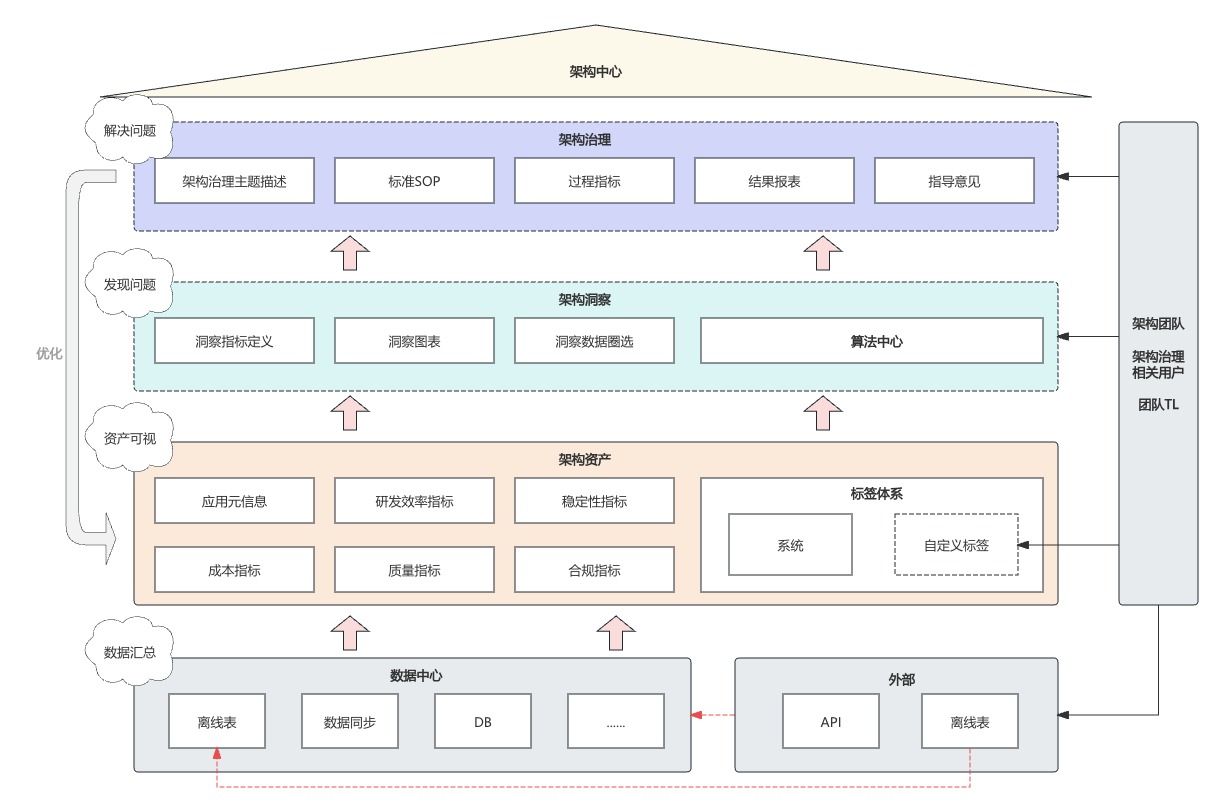
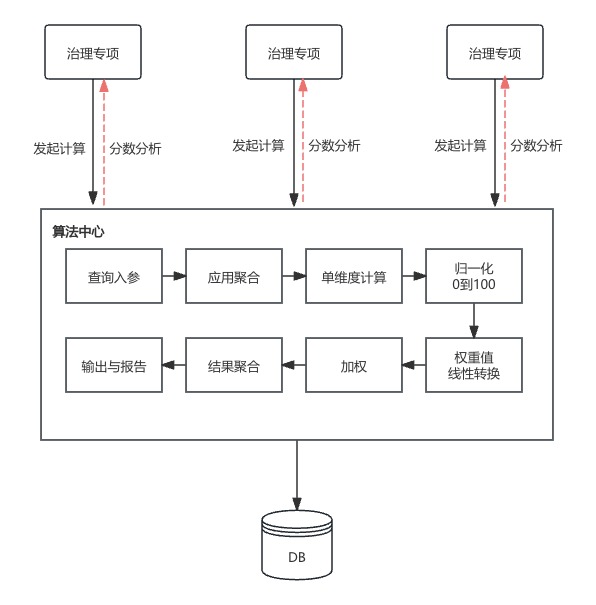
分析过程流程化、结果可视化
如上图,在定义好分析维度和分析过程之后,可以结合产品化,搭建架构治理中心,将分析过程流程化、结果可视
其中分析过程一定是严格按照敏感点和权衡点展开,得到一个服务/应用的完整画像,然后可以根据算法得到一个指导性分数。